Bibliography
[ABC+16] M. Abadi, P. Barham, J. Chen, et al. TensorFlow: a system for large-scale machine learning. OSDI, 2016.
[ACG+16] M. Abadi, A. Chu, I. Goodfellow, H. McMahan, I. Mironov, K. Talwar, and L. Zhang. Deep learning with differential privacy. CCS, Oct. 2016.
[AA16] M. Abadi and D. Andersen. Learning to protect communications with adversarial neural cryptography. Oct. 2016.
[ARS+20] D. Abts, J. Ross, J. Sparling, et al. Think fast: a tensor streaming processor (TSP) for accelerating deep learning workloads. ISCA, Jun. 2020.
[AGM+18] J. Adebayo, J. Gilmer, M. Muelly, I. Goodfellow, M. Hardt, and B. Kim. Sanity checks for saliency maps. NeurIPS, Dec. 2018.
[AMP+19] A. Agrawal, A. Modi, A. Passos, et al. TensorFlow Eager: a multi-stage, Python-embedded DSL for machine learning (slides). MLSys, Feb. 2019.
[AAB+19] Z. Ahmed, S. Amizadeh, M. Bilenko, et al. Machine learning at Microsoft with ML .NET. SIGKDD, Jul. 2019.
[ALV08] M. Al-Fares, A. Loukissas, and A. Vahdat. A scalable, commodity data center network architecture. SIGCOMM, Oct. 2008.
[Ala18] J. Alammar. The illustrated transformer. June 2018.
[Ali20] Alibaba. Machine Learning Platform for AI. 2020.
[AHJ+18] D. Alistarh, T. Hoefler, M. Johansson, S. Khirirat, N. Konstantinov, and C. Renggli. The convergence of sparsified gradient methods. NeurIPS, Dec. 2018.
[AVG+15] L. Alvarez, L. Vilanova, M. Gonzalez, X. Martorell, N. Navarro, and E. Ayguade. Hardware-software coherence protocol for the coexistence of caches and local memories. TC, Jan. 2015.
[Ama19] Amazon. EC2 Inf1 Instances. 2019.
[Ama19b] Amazon. AWS re:Invent 2019: deliver high performance ML inference with AWS Inferentia. Dec. 2019.
[Ama20] Amazon. SageMaker. 2020.
[Amd19] Amd. EPYC 7742. 2019.
[Amd67] G. Amdahl. Validity of the single processor approach to achieving large scale computing capabilities. AFIPS, Apr. 1967.
[AAB+15] D. Amodei, R. Anubhai, E. Battenberg, et al. Deep Speech 2: end-to-end speech recognition in English and Mandarin. ICML, Dec. 2015.
[AC16] D. Amodei and J. Clark. Faulty reward functions in the wild. OpenAI, Dec. 2016.
[DH18] D. Amodei and D. Hernandez. AI and compute. OpenAI, May 2018.
[AES19] A. Antoniou, H. Edwards, and A. Storkey. How to train your MAML. ICLR, Mar. 2019.
[AP19] S. Arik and T. Pfister. ProtoAttend: attention-based prototypical learning. Sep. 2019.
[ABF+19] N. Arivazhagan, A. Bapna, O. Firat, et al. Massively multilingual neural machine translation in the wild: findings and challenges. July 2019.
[ACB17] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein GAN. Jan. 2017.
[ADC11] T. Ashby, P. Diaz, and M. Cintra. Software-based cache coherence with hardware-assisted selective self-invalidations using Bloom filters. TC, Apr. 2011.
[AFO18] S. Ashkiani, M. Farach-Colton, and J. Owens. A dynamic hash table for the GPU. IPDPS, May 2018.
[ACW18] A. Athalye, N. Carlini, and D. Wagner. Obfuscated gradients give a false sense of security: circumventing defenses to adversarial examples. ICML, Jul. 2018.
[BKH16] J. Ba, J. Kiros, and G. Hinton. Layer normalization. July 2016.
[BGJ+18] V. Bacoyannis, V. Glukhov, T. Jin, J. Kochems, and D. Song. Idiosyncrasies and challenges of data driven learning in electronic trading. NeurIPS, Dec. 2018.
[BKK18] S. Bai, J. Kolter, and V. Koltun. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. Mar. 2018.
[BKK19] S. Bai, J. Kolter, and V. Koltun. Deep equilibrium models. NeurIPS, Dec. 2019.
[Bai20] Baidu. Kunlun. 2020.
[BES+19] P. Balaprakash, R. Egele, M. Salim, V. Vishwanath, F. Xia, T. Brettin, and R. Stevens. Scalable reinforcement learning based neural architecture search for cancer deep learning research. SC, Nov. 2019.
[BV20] M. Balunovic and M. Vechev. Adversarial training and provable defenses: bridging the gap. ICLR, Feb. 2020.
[BHR18] L. Barroso, U. Holze, and P. Ranganathan. The datacenter as a computer: designing warehouse-scale machines. Springer, Oct. 2018.
[BTV06] H. Bay, T. Tuytelaars, and L. Van Gool. SURF: speeded up robust features. ECCV, 2006.
[BLK+19] F. Belletti, K. Lakshmanan, W. Krichene, et al. Scaling up collaborative filtering data sets through randomized fractal expansions. Apr. 2019.
[Ben12] Y. Bengio. Practical recommendations for gradient-based training of deep architectures. NNs: Tricks of the Trade, Sep. 2012.
[BBC+19] C. Berner, G. Brockman, B. Chan, et al. Dota 2 with large scale deep reinforcement learning. Dec. 2019.
[BCC+19] D. Berg, R. Chirravuri, R. Cledat, S. Goyal, F. Hamad, and V. Tuulos. Open-sourcing Metaflow, a human-centric framework for data science. Netflix Tech Blog, Dec. 2019.
[Ber19] Berkeley. Ray. 2019.
[BDD+20] M. Binkowski, J. Donahue, S. Dieleman, et al. High fidelity speech synthesis with adversarial networks. ICLR, Apr. 2020.
[BHH20] P. Blanchard, D. Higham, and N. Higham Accurately computing the log-sum-exp and softmax functions. J. Num. Analysis, Aug. 2020.
[BCK+15] C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. Weight uncertainty in neural networks. ICML, July 2015.
[BCZ+16] T. Bolukbasi, K. Chang, J. Zou, V. Saligrama, and A. Kalai. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. NeurIPS, Dec. 2016.
[BIK+17] K. Bonawitz, V. Ivanov, B. Kreuter, et al. Practical secure aggregation for privacy-preserving machine learning. CCS, Oct. 2017.
[BHR+08] U. Bondhugula, A. Hartono, J. Ramanujam, and P. Sadayappan. A practical automatic polyhedral parallelizer and locality optimizer. SIGPLAN, June 2008.
[BAC16] U. Bondhugula, A. Acharya, and A. Cohen. The Pluto+ algorithm: A practical approach for parallelization and locality optimization of affine loop nests. TOPLAS, Apr. 2016.
[BLB17] A. Botev, G. Lever, and D. Barber. Nesterov's accelerated gradient and momentum as approximations to regularised update descent. IJCNN, Jul. 2017.
[BCD+18] T. Boyd, Y. Cao, S. Das, T. Joerg, and J. Lebar. Pushing the limits of GPU performance with XLA. Nov. 2018.
[BGL+93] J. Bromley, I. Guyon, Y. LeCun, E. Sackinger, and R. Shah. Signature verification using a "Siamese" time delay neural network. NeurIPS, Dec. 1993.
[Bro19] Y. Brovman. Complementary item recommendations at eBay scale. Feb. 2019.
[BMR+20] T. Brown, B. Mann, N. Ryder, M. Subbiah, et al. Language models are few-shot learners. May 2020.
[BCN06] C. Bucila, R. Caruana, and A. Niculescu-Mizil. Model compression. SIGKDD, Aug. 2006.
[BEP+18] Y. Burda, H. Edwards, D. Pathak, A. Storkey, T. Darrell, and A. Efros. Large-scale study of curiosity-driven learning. Aug. 2018.
[CZH19] H. Cai, L. Zhu, and S. Han. ProxylessNAS: direct neural architecture search on target task and hardware. ICLR, Feb. 2019.
[CBG+20] L. Cambier, A. Bhiwandiwalla, T. Gong, O. H. Elibol, M. Nekuii, and H. Tang. Shifted and squeezed 8-bit floating point format for low-precision training of deep neural networks. ICLR, Jan. 2020.
[HSW+18] Z. Cao, G. Hidalgo, T. Simon, S. Wei, and Y. Sheikh. OpenPose: realtime multi-person 2D pose estimation using part affinity fields. CVPR, Dec. 2018.
[CLN+17] I. Caspi, G. Leibovich, G. Novik, and S. Endrawis. Reinforcement Learning Coach. Dec. 2017.
[CMG+18] P. Castro, S. Moitra, C. Gelada, S. Kumar, and M. Bellemare. Dopamine: a research framework for deep reinforcement learning. Dec. 2018.
[CJL+16] W. Chan, N. Jaitly, Q. Le, and O. Vinyals. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition. ICASSP, 2016.
[CFL20] O. Chang, L. Flokas, and H. Lipson. Principled weight initialization for hypernetworks. ICLR, Feb. 2020.
[CCS+17] P. Chaudhari, A. Choromanska, S. Soatto, et al. Entropy-SGD: biasing gradient descent into wide valleys. ICLR, Mar. 2017.
[CBH+11] N. Chawla, K. Bowyer, L. Hall, and W. Kegelmeyer. SMOTE: synthetic minority over-sampling technique. JAIR, June 2011.
[CHM+19] Y. Chebotar, A. Handa, V. Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox. Closing the sim-to-real loop: adapting simulation randomization with real world experience. ICRA, May 2019.
[CXZ+16] T. Chen, B. Xu, C. Zhang, and C. Guestrin. Training deep nets with sublinear memory cost. Apr. 2016.
[CES16] Y. Chen, J. Emer, and V. Sze. Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks. ISCA, June 2016.
[CG16] T. Chen and C. Guestrin. XGBoost: a scalable tree boosting system. SIGKDD, Aug. 2016.
[CPS+17] L. Chen, G. Papandreou, F. Schroff, and H. Adam. Rethinking Atrous convolution for semantic image segmentation. June 2017.
[CES17] Y. Chen, J. Emer, and V. Sze. Using dataflow to optimize energy efficiency of deep neural network accelerators. MICRO, June 2017.
[CMJ+18] T. Chen, T. Moreau, Z. Jiang, et al. TVM: an automated end-to-end optimizing compiler for deep learning. OSDI, 2018.
[CYC19] C. Chen, C. Yang, and H. Cheng. Efficient and robust parallel DNN training through model parallelism on multi-GPU platform. Oct. 2019.
[CZZ+19] C. Chen, M. Zhang, M. Zhang, Y. Liu, Y. Li, and S. Ma. Social attentional memory network: modeling aspect- and friend-level differences in recommendation. WSDM, Jan. 2019.
[CZL+19] Q. Chen, H. Zhao, W. Li, P. Huang, and W. Ou. Behavior sequence transformer for e-commerce recommendation in Alibaba. DLP-KDD, Aug. 2019.
[CMF+20] B. Chen, T. Medini, J. Farwell, S. Gobriel, C. Tai, and A. Shrivastava. SLIDE : in defense of smart algorithms over hardware acceleration for large-scale deep learning systems. MLSys, Mar. 2020.
[CYE+19] Y. Chen, T. Yang, J. Emer, and V. Sze. Eyeriss v2: a flexible accelerator for emerging deep neural networks on mobile devices. JETCAS, June 2019.
[CKH+16] H. Cheng, L. Koc, J. Harmsen, et al. Wide and deep learning for recommender systems. DLRS, Sep. 2016.
[CWV+14] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer. cuDNN: efficient primitives for deep learning. Dec. 2014.
[CCK+17] Y. Choi, M. Choi, M. Kim, J. Ha, S. Kim, and J. Choo. StarGAN: unified generative adversarial networks for multi-domain image-to-image translation. CVPR, Nov. 2017.
[CWV+18] J. Choi, Z. Wang, S. Venkataramani, P. Chuang, V. Srinivasan, and K. Gopalakrishnan. PACT: parameterized clipping activation for quantized neural networks. July 2018.
[Cho16] F. Chollet. Xception: deep learning with depthwise separable convolutions. CVPR, Oct. 2016.
[CB18] N. Choma and J. BrunaY. Graph neural networks for neutrino classification. Big Data Summit, Feb. 2018.
[CGC+14] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. Dec. 2014.
[CFO+18] E. Chung, J. Fowers, K. Ovtcharov, et al. Serving DNNs in real time at datacenter scale with project Brainwave. MICRO, Mar. 2018.
[CAL+16] O. Cicek, A. Abdulkadir, S. Lienkamp, T. Brox, and O. Ronneberger. 3D U-Net: learning dense volumetric segmentation from sparse annotation. MICCAI, June 2016.
[Cor20] Cortex. Deploy machine learning models in production. 2020.
[CAS16] P. Covington, J. Adams, and E. Sargin. Deep neural networks for YouTube recommendations. RecSys, Sep. 2016.
[DCJ19] M. Dacrema, P. Cremonesi, and D. Jannach. Are we really making much progress? A worrying analysis of recent neural recommendation approaches. RecSys, Sep. 2019.
[DB19] W. Dai and D. Berleant. Benchmarking contemporary deep learning hardware and frameworks: a survey of qualitative metrics. CogMI, Dec. 2019.
[Dal17] B. Dally. High-performance hardware for machine learning. ENN, Feb. 2017.
[DAM+16] D. Das, S. Avancha, D. Mudigere, et al. Distributed deep learning using synchronous stochastic gradient descent. Feb. 2016.
[DMM+18] D. Das, N. Mellempudi, D. Mudigere, et al. Mixed precision training of convolutional neural networks using integer operations. ICLR, Feb. 2018.
[DPG+14] Y. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Ganguli, and Y. Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. NeurIPS, Dec. 2014.
[DKA+19] S. Dave, Y. Kim, S. Avancha, K. Lee, and A. Shrivastava. DMazeRunner: executing perfectly nested loops on dataflow accelerators. TECS, Oct. 2019.
[Daw20] DAWNBench. DAWNBench: an end-to-end deep learning benchmark and competition. 2020.
[Dee19] DeepBench. Benchmarking deep learning operations on different hardware. 2019.
[DGY+74] R. Dennard, F. Gaensslen, H. Yu, V. Rideout, E. Bassous, and A. LeBlanc. Design of ion-implanted MOSFET's with very small physical dimensions. JSSC, Oct. 1974.
[DAM+19] D. Dennis, D. Acar, V. Mandikal, V. Sadasivan, H. Simhadri, V. Saligrama, and P. Jain. Shallow RNNs: a method for accurate time-series classification on tiny devices. NeurIPS, Dec. 2019.
[Dev17] J. Devlin. Sharp models on dull hardware: fast and accurate neural machine translation decoding on the CPU. May 2017.
[DCL+18] J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. Oct. 2018.
[DAL+18] G. Dhillon, K. Azizzadenesheli, Z. Lipton, et al. Stochastic activation pruning for robust adversarial defense. ICLR, Mar. 2018.
[dDF+19] F. de Dinechin, L. Forget, J. Muller, and Y. Uguen. Posits: the good, the bad and the ugly. CoNGA, Mar. 2019.
[DSK+19] Y. Ding, J. Sohn, M. Kawczynski, et al. A deep learning model to predict a diagnosis of Alzheimer disease by using F-FDG PET of the brain. Radiology, Feb. 2019.
[DPB+17] L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio. Sharp minima can generalize for deep nets. ICML, Aug. 2017.
[DWO+19] Z. Doctor, D. Wysocki, R. O'Shaughnessy, D. Holz, and B. Farr. Black hole coagulation: modeling hierarchical mergers in black hole populations. Nov. 2019.
[DDV+20] T. Domhan, M. Denkowski, D. Vilar, X. Niu, F. Hieber, and K. Heafield. The Sockeye 2 neural machine translation toolkit at AMTA 2020. Aug. 2020.
[Don19] L. Dong. eBay's hyperscale platforms. Sep. 2019.
[DYC+19] Z. Dong, Z. Yao, Y. Cai, D. Arfeen, A. Gholami, M. Mahoney, and K. Keutzer. HAWQ-V2: Hessian aware trace-weighted quantization of neural networks. Nov. 2019.
[Doz16] T. Dozat. Incorporating Nesterov momentum into Adam. ICLR, May 2016.
[DMM+19] N. Dryden, N. Maruyama, T. Moon, T. Benson, M. Snir, and B. Van Essen. Channel and filter parallelism for large-scale CNN training. SC, Nov. 2019.
[DJS20] M. Du, R. Jia, and D. Song. Robust anomaly detection and backdoor attack detection via differential privacy. ICLR, Feb. 2020.
[DHS11] J. Duchji, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. JMLR, July 2011.
[Efr20] A. Efrati. AI startups proliferate as businesses look for savings. The Information, Aug. 2020.
[ERR+18] V. Elango, N. Rubin, M. Ravishankar, H. Sandanagobalane, and V. Grover. Diesel: DSL for linear algebra and neural net computations on GPUs. MAPL, June 2018.
[ENG+18] A. Eisenman, M. Naumov, D. Gardner, M. Smelyanskiy, S. Pupyrev, K. Hazelwood, A. Cidon, and S. Katti. Bandana: using non-volatile memory for storing deep learning models. Nov. 2018.
[ETT15] T. Erez, Y. Tassa, and E. Todorov. Simulation tools for model-based robotics: comparison of Bullet, Havok, MuJoCo, ODE and PhysX. ICRA, May 2015.
[EBA+11] H. Esmaeilzadeh, E. Blem, R. S. Amant, K. Sankaralingam, and D. Burger. Dark silicon and the end of multicore scaling. ISCA, June 2011.
[EG16] R. Evans and J. Gao. DeepMind AI reduces Google data centre cooling bill by 40 percent. July 2016.
[Fac18] Facebook. Glow IR. Oct. 2018.
[Fac20] Facebook. Compiler for neural network hardware accelerators. Feb. 2020.
[FHY19] F. Farshchi, Q. Huang, and H. Yun. Integrating NVIDIA deep learning accelerator (NVDLA) with RISC-V SoC on FireSim. EMC2, Dec. 2019.
[Fel19] M. Feldman. AI recommendation systems get a GPU makeover. 2018.
[Fel19b] A. Feldman. Cerebras deploys the CS-1, the industry's fastest AI computer, at Argonne National Lab. Nov. 2019.
[FGM+10] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. PAMI, Sep. 2010.
[Fey20] M. Fey. PyTorch geometric documentation. 2020.
[FL19] M. Fey and J. Lenssen. Fast graph representation learning with PyTorch geometric. Mar. 2019.
[FAL17] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. ICML, July 2017.
[FWT11] V. Firoiu, W. Whitney, and J. Tenenbaum. Beating the world's best at Super Smash Bros. with deep reinforcement learning. May 2017.
[FRP+20] S. Flennerhag, A. Rusu, R. Pascanu, F. Visin, H. Yin, and R. Hadsell. Meta-learning with warped gradient descent. ICLR, Apr. 2020.
[FC19] J. Frankle and M. Carbin. The lottery ticket hypothesis: finding sparse, trainable neural networks. ICLR, Mar. 2019.
[FLP+99] M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran. Cache-oblivious algorithms. 1999.
[Gab46] D. Gabor. Theory of communication. Part 1: the analysis of information. Radio & Comm. Eng., Nov. 1946.
[GZY+20] T. Gale, M. Zaharia, C. Young, and Erich Elsen. Sparse GPU kernels for deep learning. June 2020.
[GCL+19] J. Gauci, E. Conti, Y. Liang, et al. Horizon: Facebook's open source applied reinforcement learning platform. Sep. 2019.
[GMV+20] T. Gebru, J. Morgenstern, B. Vecchione, J. Vaughan, H. Wallach, H. Daume III, and K. Crawford. Datasheets for datasets. Mar, 2019.
[GAG+17] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. Dauphin. Convolutional sequence to sequence learning. ICML, May 2017.
[GRM+18] R. Geirhos, P. Rubisch, C. Michaelis, M. Bethge, F. Wichmann, and W. Brendel. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. Nov. 2018.
[Gen09] C. Gentry. A fully homomorphic encryption scheme. Sep. 2009.
[GAB+18] E. Georganas, S. Avancha, K. Banerjee, D. Kalamkar, G. Henry, H. Pabst, and A. Heinecke. Anatomy Of high-performance deep learning convolutions on SIMD architectures. SC, Aug. 2018.
[GSC99] F. Gers, J. Schmidhuber, and F. Cummins. Learning to forget: continual prediction with LSTM. ICANN, Sep. 1999.
[Gha17] A. Gharakhanian. Generative adversarial networks-hot topic in machine learning. KDnuggets, Jan. 2017.
[GAJ+18] A. Gholami, A. Azad, P. Jin, K. Keutzer, and A. Buluc. Integrated model, batch, and domain parallelism in training neural networks. SPAA, July 2018.
[GLH+19] S. Ghose, T. Li, N. Hajinazar, D. Cali, and O. Mutlu. Understanding the interactions of workloads and DRAM types: a comprehensive experimental study. Oct. 2019.
[GCH+20] B. Ginsburg, P. Castonguay, O. Hrinchuk, et al. Stochastic gradient methods with layer-wise adaptive moments for training of deep networks. Feb. 2020.
[GBB11] X. Glorot, A. Bordes, and Y. Bengio. Deep sparse rectifier neural networks. AISTATS, 2011.
[GB10] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. AISTATS, 2010.
[GPM+14] I. Goodfellow, J. Pouget-Abadie, M. Mirza, et al. Generative adversarial networks. Jun. 2014.
[Goo19] Google. MLIR: a new intermediate representation and compiler framework. Apr. 2019.
[Goo20] Google. Embeddings: translating to a lower-dimensional space. 2020.
[Goo20b] Google. C++ differential privacy library. Feb. 2020.
[Goo20c] Google. XLA: optimizing compiler for machine learning. Feb. 2020.
[Goo20d] Google. AI Platform. 2020.
[Goo20e] Google. TensorFlow Extended (TFX) is an end-to-end platform for deploying production ML pipelines. 2020.
[Goo20f] Google. TensorFlow TCAV. 2020.
[Gvd08] K. Goto, and R. van de Geijn. Anatomy of high-performance matrix multiplication. TOMS, May 2008.
[Gra19] GraphCore. Microsoft and Graphcore collaborate to accelerate artificial intelligence. 2019.
[Gra20] Graphcore. Intelligent processing unit. July 2020.
[GSK+17] K. Greff, R. Srivastava, J. Koutn\'{\i}k, B. Steunebrink, and J. Schmidhuber. LSTM: a search space dyssey. TNNLS, Oct. 2017.
[GW00] A. Griewank and A. Walther. Algorithm 799: revolve: an implementation of checkpointing for the reverse or adjoint mode of computational differentiation. TOMS, Mar. 2000.
[GMY+19] H. Guan, A. Malevich, J. Yang, Jongsoo Park, and H. Yuen. Post-training 4-bit quantization on embedding tables. NeurIPS, Dec. 2019.
[GWY+19] S. Gui, H. Wang, C. Yu, H. Yang, Z. Wang, and J. Liu. Model compression with adversarial robustness: a unified optimization framework. NeurIPS, Dec. 2019.
[Gui20] GuildAI. The ML Engineering Platform. 2020.
[GVW21] D. Gunning, E. Vorm, and J. Wang DARPA's explainable AI (XAI) program: a retrospective. DARPA, Dec. 2021.
[GPV+20] P. Gupta, N. Puri, S. Verma, D. Kayastha, S. Deshmukh, B. Krishnamurthy, and S. Singh. Explain your move: understanding agent actions using focused feature saliency. ICLR, 2020.
[GTY+17] H. Guo, R. Tang, Y. Ye, Z. Li, and X. He. DeepFM: a factorization-machine based neural network for CTR prediction. Mar. 2017.
[Gus17] J. Gustafson. Posit arithmetic. 2017.
[Hab19] Habana Labs. Goya inference platform white paper. Aug. 2019.
[Hab19b] Habana Labs. System-1. June 2019.
[HKK16] D. Han, J. Kim, and J. Kim. Deep pyramidal residual networks. CVPR, Oct. 2016.
[HPN+17] S. Han, J. Pool, S. Narang, et al. DSD: dense-sparse-dense training for deep neural networks. ICLR, Feb. 2017.
[HRM+19] A. Hard, K. Rao, R. Mathews, et al. Federated learning for mobile keyboard prediction. Feb. 2019.
[HNP+18] A. Harlap, D. Narayanan, A. Phanishayee, V. Seshadri, N. Devanur, G. Ganger, and P. Gibbons. PipeDream: fast and efficient pipeline parallel DNN training. June 2018.
[Har18] F. Hartmann. Federated learning for Firefox. Aug. 2018.
[Has18] M. Hassan. AlexNet-1.png. 2018.
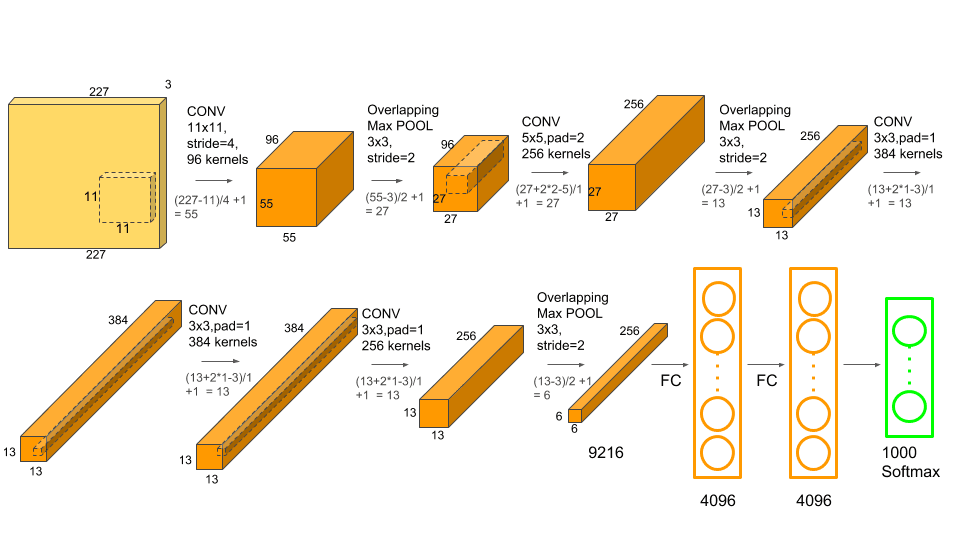{kind=link}
[Haz18] K. Hazelwood. Applied machine learning at Facebook: an infrastructure perspective. Sep. 2018.
[HBB+18] K. Hazelwood, S. Bird, D. Brooks, et al. Applied machine learning at Facebook: a datacenter infrastructure perspective. HPCA, Feb. 2018.
[Haz20] K. Hazelwood. Deep learning: it's not all about recognizing cats and dogs. SAIS, June 2020.
[HBG+08] H. He, Y. Bai, E. A. Garcia, and S. Li. ADASYN: adaptive synthetic sampling approach for imbalanced learning. IJCNN, June 2008.
[HZR+15] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. CVPR, Dec. 2015.
[HZR+15] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. ICCV, Feb. 2015.
[HZR+15] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. Apr. 2015.
[HGD+17] K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask R-CNN. ICCV, Mar. 2017.
[HLZ+17] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T. Chua. Neural collaborative filtering. ICIWWW, Apr. 2017.
[HSP+19] Y. He, T. Sainath, R. Prabhavalkar, et al. Streaming end-to-end speech recognition for mobile devices. ICASSP, Apr. 2019.
[HLL+19] Y. He, J. Lin, Z. Liu, H. Wang, L. Li, and S. Han. AMC: AutoML for model compression and acceleration on mobile devices. ECCV, Jan. 2019.
[HAP+19] K. Hegde, H. Asghari-Moghaddam, M. Pellauer, et al. ExTensor: an accelerator for sparse tensor algebra. MICRO, Oct. 2019.
[HIB+19] P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger. Deep Reinforcement Learning that Matters. Jan. 2019.
[HG16] D. Hendrycks and K. Gimpel. Gaussian error linear units (GELUs). June 2016.
[HDB18] J. Hermann and M. Del Balso. Meet Michelangelo: Uber's machine learning platform. Nov. 2018.
[HMv+17] M. Hessel, J. Modayil, H. van Hasselt, et al. Rainbow: combining improvements in deep reinforcement learning. AAAI, Oct. 2017.
[HR15] T. Highlander and A. Rodriguez. Very efficient training of convolutional neural networks using fast Fourier transform and overlap-and-add. BMVA, Sep. 2015.
[HSS12] G. Hinton, N. Srivastava, and K. Swersky. RMSProp: divide the gradient by a running average of its recent magnitude. Coursera, 2012.
[HVD15] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. Mar. 2015.
[HAP17] B. Hitaj, G. Ateniese, and F. Perez-Cruz. Deep models under the GAN: information leakage from collaborative deep learning. SIGSAC CCS, Sep. 2017.
[HS97] S. Hochreiter and J. Schmidhuber. Flat minima. Neural Comp., Jan. 1997.
[HS97] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Comp., Nov. 1997.
[HHS17] E. Hoffer, I. Hubara, and D. Soudry. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. NeurIPS, Dec. 2017.
[HM19] A. Holler and M. Mui. Evolving Michelangelo model representation for flexibility at scale. Oct. 2019.
[HEK+19] S. Hooker, D. Erhan, P. Kindermans, and B. Kim. A benchmark for interpretability methods in deep neural networks. NeurIPS, Dec. 2019.
[HSW89] K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators. NNs, Mar. 1989.
[Hor14] M. Horowitz. 1.1 Computing's energy problem (and what we can do about it). ISSCC, Feb. 2014.
[Hou19] J. Hou. New research on quantization could revolutionize power-efficient AI. July 2019.
[HZC+17] A. G. Howard, M. Zhu, B. Chen, et al. MobileNets: efficient convolutional neural networks for mobile vision applications. Apr. 2017.
[HSA+19] J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu. Squeeze-and-excitation networks. CVPR, May 2019.
[HLG+19] W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V. Pande, and J. Leskovec. Strategies for pre-training graph neural networks. ICLR, Sep. 2019.
[HZS+19] W. Hua, Y. Zhou, C. Sa, Z. Zhang, and G. Suh. Channel gating neural networks. NeurIPS, Dec. 2019.
[HLv+16] G. Huang, Z. Liu, L. van der Maaten, and K. Weinberger. Densely connected convolutional networks. CVPR, Aug. 2016.
[HLP+17] X. Huang, Y. Li, O. Poursaeed, J. Hopcroft, and S. Belongie. Stacked generative adversarial networks. CVPR, June 2017.
[HCB+19] Y. Huang, Y. Cheng, A. Bapna, et al. GPipe: efficient training of giant neural networks using pipeline parallelism. NeurIPS, Dec. 2019.
[HDS+19] D. Huang, P. Dhariwal, D. Song, and I. Sutskever. GamePad: a learning environment for theorem proving. ICLR, 2019.
[Hug15] C. Hughes. Single-instruction multiple-data execution. Springer, May 2015.
[HS14] K. Hwang and W. Sung. Fixed-point feedforward deep neural network design using weights +1, 0, and -1. SiPS, Oct. 2014.
[IHM+16] F. Iandola, S. Han, M. Moskewicz, K. Ashraf, W. Dally, and K. Keutzer. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. CVPR, Feb. 2016.
[Ibm20] IBM. IBM reveals next-generation IBM POWER10 processor. Aug. 2020.
[Int18] Intel. Knowledge Distillation. 2018.
[Int19] Intel. Next-generation Intel Xeon Scalable processors to deliver breakthrough platform performance with up to 56 processor cores. Aug. 2019.
[Int19b] Intel. Aurora SuperComputer. Nov. 2019.
[Int20] Intel. Innovation through intelligence. Jan. 2020.
[Int20b] Intel. Intel architecture instruction set extensions and future features programming reference. June 2020.
[Int20c] Intel. Analytics zoo. 2020.
[IS15] S. Ioffe and C. Szegedy. Batch normalization: accelerating deep network training by reducing internal covariate shift. Feb. 2015.
[Iof17] S. Ioffe. Batch renormalization: towards reducing minibatch dependence in batch-normalized models. NeurIPS, Dec. 2017.
[IZZ+16] P. Isola, J. Zhu, T. Zhou, and A. Efros. Image-to-image translation with conditional adversarial networks. CVPR, Nov. 2016.
[Iva71] A. Ivakhnenko. Polynomial theory of complex systems. SMC, Oct. 1971.
[IPG+19] P. Izmailov, D. Podoprikhin, T. Garipov, D. Vetrov, and A. Wilson. Averaging weights leads to wider optima and better generalization. UAI, Feb. 2019.
[Jad19] A. Jadhav. Applications of graph neural networks. Feb. 2019.
[JJN+19] P. Jain, A. Jain, A. Nrusimha, A. Gholami, P. Abbeel, K. Keutzer, I. Stoica, and J. Gonzalez. Checkmate: breaking the memory wall with optimal tensor rematerialization. Oct. 2019.
[JFZ+19] M. Janner, J. Fu, M. Zhang, and S. Levine. When to trust your model: model-based policy optimization. NeurIPS, Dec. 2019.
[JYS19] D. Jauk, D. Yang, and M. Schulz. Predicting faults in high performance computing systems: an in-depth survey of the state-of-the-practice. SC, Nov. 2019.
[Jax20] Jax. Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more. Feb. 2020.
[JJM+18] Y. Jia, M. Johnson, W. Macherey, et al. Leveraging weakly supervised data to improve end-to-end speech-to-text translation. ICASSP, Nov. 2018.
[JWB+19] Y. Jia, R. Weiss, F. Biadsy, W. Macherey, M. Johnson, Z. Chen, and Y. Wu. Direct speech-to-speech translation with a sequence-to-sequence model. Apr. 2019.
[JZW+18] Y. Jia, Y. Zhang, R. Weiss, et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. NeurIPS, Dec. 2018.
[JZA18] Z. Jia, M. Zaharia, and A. Aiken. Beyond data and model parallelism for deep neural networks. ML, July 2018.
[JHJ+20] Y. Jiao, L. Han, R. Jin, et al. 12nm programmable convolution-efficient neural-processing-unit chip achieving 825 TOPS. ISSCC, Feb. 2020.
[JGK18] P. Jin, B. Ginsburg, and K. Keutzer. Spatially parallel convolution. ICLR, 2018.
[Joh18] J. Johnson. Rethinking floating point for deep learning. NeurIPS, Dec. 2018.
[JS18] M. Johnson and B. Stevens. Pruning hypothesis comes of age. Nature, Feb. 2018.
[JYv19] J. Jordon, J. Yoon, and M. van der Schaar. PATE-GAN: generating synthetic data with differential privacy guarantees. ICLR, Feb. 2019.
[JYP+17] N. Jouppi, C. Young, N. Patil, D. Patterson, et al. In-datacenter performance analysis of a tensor processing unit. ISCA, June 2017.
[JYK+20] N. Jouppi, D. Yoon, G. Kurian, S. Li, N. Patil, J. Laudon, C. Young, and D. Patterson. A domain-specific supercomputer for training deep neural networks. CACM, July 2020.
[JZS15] R. Jozefowicz, W. Zaremba, and I. Sutskever. An empirical exploration of recurrent network architectures. ICML, July 2015.
[KZK+19] D. Kaji, J. Zech, J. Kim, S. Cho, N. Dangayach, A. Costa, and E. Oermann. An attention based deep learning model of clinical events in the intensive care unit. Feb. 2019.
[KES+18] N. Kalchbrenner, E. Elsen, K. Simonyan, et al. Efficient neural audio synthesis. June 2018.
[KMM+19] D. Kalamkar, D. Mudigere, N. Mellempudi, et al. A study of bfloat16 for deep learning training. June 2019.
[KMH+20] J. Kaplan, S. McCandlish, T. Henighan, T. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. Jan. 2020.
[KBA18] S. Karandikar, D. Biancolin, and A. Amid. FireSim. 2018.
[KCH+19] S. Karita, N. Chen, T. Hayashi, et al. A comparative study on transformer vs RNN in speech applications. Sep. 2019.
[Kar19] A. Karpathy. A recipe for training neural networks. Apr. 2019.
[KLA19] T. Karras, S. Laine, and T. Aila. A style-based generator architecture for generative adversarial networks. CVPR, Mar. 2019.
[KR19] S. Katariya and A. Ramani. eBay's transformation to a modern AI platform. Dec. 2019.
[KMN+17] N. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. Tang. On large-batch training for deep learning: generalization gap and sharp minima. ICLR, Apr. 2017.
[KS17] N. Keskar and R. Socher. Improving generalization performance by switching from Adam to SGD. Dec. 2017.
[KDT+05] J. Kim, W. Dally, B. Towles, and A. Gupta. Microarchitecture of a high-radix router. ISCA, June 2005.
[KDS+08] J. Kim, W. Dally, S. Scott, and D. Abts. Technology-driven, highly-scalable dragonfly topology. ISCA, June 2008.
[KWG+18] B. Kim, M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viegas, and R. Sayres. Interpretability beyond feature attribution: quantitative testing with concept activation vectors (TCAV). ICML, June 2018.
[KKS+19] C. Kim, S. Kang, D. Shin, S. Choi, Y. Kim, and H. Yoo. A 2.1TFLOPS/W mobile deep RL accelerator with transposable PE array and experience compression. ISSCC, Feb. 2019.
[KB17] D. Kingma and J. Ba. Adam: a method for stochastic optimization. ICLR, Jan. 2017.
[KKC+17] F. Kjolstad, S. Kamil, S. Chou, D. Lugato, and S. Amarasinghe. The tensor algebra compiler. OOPSLA, Oct. 2017.
[KUM+17] G. Klambauer, T. Unterthiner, A. Mayr, and S. Hochreiter. Self-normalizing neural networks. NeurIPS, Dec. 2017.
[Kod19] R. Koduri. Intel unveils new GPU architecture with high-performance computing and AI acceleration, and oneAPI software stack with unified and scalable abstraction for heterogeneous architectures. Intel HPC Dev. Conf., Nov. 2019.
[KSA+15] R. Komuravelli, M. Sinclair, J. Alsop, et al. Stash: have your scratchpad and cache it too. ISCA, Oct. 2015.
[KMY+17] J. Konecny, H. McMahan, F. Yu, P. Richtarik, A. Suresh, and D. Bacon. Federated learning: strategies for improving communication efficiency. Oct. 2017.
[KCV+20] A. Kosson, V. Chiley, A. Venigalla, J. Hestness, and U. Koster. Pipelined backpropagation at scale: training large models without batches. Mar. 2020.
[KWW+17] U. Koster, T. Webb, X. Wang, et al. Flexpoint: an adaptive numerical format for efficient training of deep neural networks. NeurIPS, Dec. 2017.
[KL19] W. Kouw and M. Loog. An introduction to domain adaptation and transfer learning. Jan. 2019.
[KBC+18] T. Kraska, A. Beutel, E. H. Chi, J. Dean, and N. Polyzotis. The case for learned index structures. Apr. 2018.
[KSH12] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. NeurIPS, Dec. 2012.
[Kri14] A. Krizhevsky. One weird trick for parallelizing convolutional neural networks. Apr. 2014.
[KGG+18] O. Kuchaiev, B. Ginsburg, I. Gitman, et al. Mixed-precision training for NLP and speech recognition with OpenSeq2Seq. Nov. 2018.
[LMM+19] I. Laguna, R. Marshall, K. Mohror, M. Ruefenacht, A. Skjellum, and N. Sultana. A large-scale study of MPI usage in open-source HPC applications. SC, Nov. 2019.
[LCG+19] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut. ALBERT: a lite BERT for self-supervised learning of language representations. Sep. 2019.
[LS19] R. Larsen and T. Shpeisman. TensorFlow graph optimizations. 2019.
[LA04] C. Lattner and V. Adve. LLVM: a compilation framework for lifelong program analysis \& transformation. CGO, Mar. 2004.
[LP19] C. Lattner and J. Pienaar. MLIR primer: a compiler infrastructure for the end of Moore's Law. CGO, Feb. 2019.
[LG16] A. Lavin and S. Gray. Fast algorithms for convolutional neural networks. CVPR, Sep. 2015.
[Lec16] Y. Lecun. RI seminar: Yann LeCun : the next frontier in AI: unsupervised learning. Nov. 2016.
[LBB+98] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. IEEE, Nov. 1998.
[LDS89] Y. Lecun, J. Denker, and S. Solla. Optimal brain damage. NeurIPS, 1989.
[LAG+19] M. Lecuyer, V. Atlidakis, R. Geambasu, D. Hsu, and S. Jana. Certified robustness to adversarial examples with differential privacy. S\&P, May 2019.
[LTH+16] C. Ledig, L. Theis, F. Huszar, et al. Photo-realistic single image super-resolution using a generative adversarial network. CVPR, Sep. 2016.
[LMC+17] E. Lee, D. Miyashita, E. Chai, B. Murmann, and S. Wong. LogNet: energy-efficient neural networks using logarithmic computation. ICASSP, Mar. 2017.
[LLH+19] J. Lee, J. Lee, D. Han, J. Lee, G. Park, and H. Yoo. 7.7 LNPU: a 25.3TFLOPS/W sparse deep-neural-network learning processor with fine-grained mixed precision of FP8-FP16. ISSCC, Feb. 2019.
[LMR+19] K. Lee, S. Maji, A. Ravichandran, and S. Soatto. Meta-learning with differentiable convex optimization. CVPR, Apr. 2019.
[LLX+20] D. Lepikhin, H. Lee, Y. Xu, et al. GShard: scaling giant models with conditional computation and automatic sharding. June 2020.
[LAS+07] J. Leverich, H. Arakida, A. Solomatnikov, A. Firoozshahian, M. Horowitz, and C. Kozyrakis. Comparing memory systems for chip multiprocessors. ISCA, June 2007.
[LM18] Y. Leviathan and Y. Matias. Google Duplex: an AI system for accomplishing real-world tasks over the phone. May 2018.
[LSZ+19] T. Li, A. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith. Federated optimization in heterogeneous networks. Sep. 2019.
[LCH+19] X. Li, S. Chen, X. Hu, and J. Yang. Understanding the disharmony between dropout and batch normalization by variance shift. CVPR, Jan. 2019.
[LKH+18] D. Liang, R. Krishnan, M. Hoffman, and T. Jebara. Variational autoencoders for collaborative tiltering. IW3C2, Feb. 2018.
[LHP+19] T. Lillicrap, J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra. Continuous control with deep reinforcement learning. July 2019.
[LGH19] J. Lin, C. Gan, and S. Han. Defensive quantization: when efficiency meets robustness. ICLR, Apr. 2019.
[LGH+16] T. Lin, P.Doll\'ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. CVPR, Dec. 2016.
[LGG+17] T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar. Focal loss for dense object detection. ICCV, Aug. 2017.
[LSP+19] T. Lin, S. Stich, K. Patel, and M. Jaggi. Don't use large mini-batches, use local SGD. June 2019.
[LHM+18] Y. Lin, S. Han, H. Mao, Y. Wang, and W. Dally. Deep gradient compression: reducing the communication bandwidth for distributed training. ICLR, Feb. 2018.
[LHL+18] P. Lindstrom, J. Hittinger, M. Larsen, S. Lloyd, and M. Salasoo. Alternatives to IEEE: NextGen number formats for scientific computing. IPAM, Oct. 2018.
[LRS+18] G. Liu, F. Reda, K. Shih, T. Wang, A. Tao, and B. Catanzaro. Image inpainting for irregular holes using partial convolutions. ECCV, Apr. 2018.
[LDR+18] L. Liu, S. Dean, E. Rolf, M. Simchowitz, and M. Hardt. Delayed impact of fair machine learning. ICML, Apr. 2018.
[LPH+18] X. Liu, J. Pool, S. Han, and W. Dally. Efficient sparse Winograd convolutional neural networks. ICLR, Feb. 2018.
[LSY19] H. Liu, K. Simonyan, and Y. Yang. DARTS: differentiable architecture search. ICLR, Apr. 2019.
[LJH+19] L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han. On the variance of the adaptive learning rate and beyond. Aug. 2019.
[LZL+19] L. Liu, J. Zhu, Z. Li, Y. Lu, Y. Deng, J. Han, S. Yin, and S. Wei. A survey of coarse-grained reconfigurable architecture and design: taxonomy, challenges, and applications. CSUR, Oct. 2019.
[LAE+15] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Fu, and A. Berg. SSD: single shot multibox detector. ECCV, Dec. 2015.
[LOG+19] Y. Liu, M. Ott, N. Goyal, et al. RoBERTa: a robustly optimized BERT pretraining approach. July 2019.
[LSZ+19] Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell. Rethinking the value of network pruning. ICLR, Mar. 2019.
[Llv20] LLVM. MLIR: the case for a simplified polyhedral form. 2020.
[LSD14] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. CVPR, Nov. 2014.
[Lor19] B. Lorica. One simple graphic: researchers love PyTorch and TensorFlow. July 2019.
[LH17] I. Loshchilov and F. Hutter. SGDR: stochastic gradient descent with warm restarts. ICLR, May 2017.
[LH19] I. Loshchilov and F. Hutter. Decoupled weight decay regularization. ICLR, Jan. 2019.
[Lov19] S. Lovely. How many titles are available on Netflix in your country?. May 2019.
[LPM15] M. Luong, H. Pham, and C. Manning. Effective approaches to attention-based neural machine translation. Aug. 2015.
[LCZ+19] S. Lym, E. Choukse, S. Zangeneh, W. Wen, S. Sanghavi, and M. Erez. PruneTrain: fast neural network training by dynamic sparse model reconfiguration. SC, Nov. 2019.
[MYM+19] L. Ma, Z. Yang, Y. Miao, J. Xue, M. Wu, L. Zhou, and Y. Dai. NeuGraph: parallel deep neural network computation on large graphs. ATC, July 2019.
[MMS+19] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. ICLR, Sep. 2019.
[MHP+17] H. Mao, S. Han, J. Pool, W. Li, X. Liu, Y. Wang, and W. Dally. Exploring the regularity of sparse structure in convolutional neural networks. NeurIPS, Dec. 2017.
[ML18] D. Masters and C. Luschi. Revisiting small batch training for deep neural networks. Apr. 2018.
[MKA+18] S. McCandlish, J. Kaplan, D. Amodei, et al. An empirical model of large-batch training. Feb. 2017.
[MMR+17] H. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Arcas. Communication-efficient learning of deep networks from decentralized data. Feb. 2017.
[MSD+19] N. Mellempudi, S. Srinivasan, D. Das, and B. Kaul. Mixed precision training with 8-bit floating point. May 2019.
[MC17] D. Meng and H. Chen. MagNet: a two-pronged defense against adversarial examples. CCS, Sep. 2017.
[Mer19] S. Merity. Single headed attention RNN: stop thinking with your head. Nov. 2019.
[Met19] Metaflow. A framework for real-life data science. 2019.
[Met19b] Metaflow. Metaflow on AWS. 2019.
[MLN19] P. Michel, O. Levy, and G. Neubig. Are sixteen heads really better than one?. NeurIPS, Dec. 2019.
[Mic20] Microsoft. ML.NET Documentation. 2020.
[Mic20b] Microsoft. Azure Cognitive services. 2020.
[Mig17] S. Migacz. 8-bit inference with TensorRT. GTC, May 2017.
[MSU+19] H. Mikami, H. Suganuma, P. U-chupala, Y. Tanaka, and Y. Kageyama. Massively distributed SGD: ImageNet/ResNet-50 training in a flash. Mar. 2019.
[MSC+13] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. NeurIPS, Dec. 2013.
[MNA16] F. Milletari, N. Navab, and S. Ahmadi. V-Net: fully convolutional neural networks for volumetric medical image segmentation. 3DV, June 2016.
[MGP+18] A. Mirhoseini, A. Goldie, H. Pham, B. Steiner, Q. Le, and J. Dean. A hierarchical model for device placement. ICLR, 2018.
[MFL+19] S. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh. Improved knowledge distillation via teacher assistant. AAAI, Dec. 2019.
[MWZ+19] M. Mitchell, S. Wu, A. Zaldivar, et al. Model cards for model reporting. Jan. 2019.
[MZH+16] I. Mitliagkas, C. Zhang, S. Hadjis, and C. Re. Asynchrony begets momentum, with an application to deep learning. Comm., Control, and Comp., Nov. 2016.
[Mlf20] MLFlow. An open source platform for the machine learning lifecycle. 2020.
[Mlp18] MLPerf. MLPerf. 2018.
[MBM+16] V. Mnih, A. Badia, M. Mirza, et al. Asynchronous methods for deep reinforcement learning. ICML, June 2016.
[KSe+13] V. Mnih, K. Kavukcuoglu, D. Silver, et al. Playing atari with deep reinforcement learning. Dec. 2013.
[MKS+15] V. Mnih, K. Kavukcuoglu, D. Silver, et al. Human-level control through deep reinforcement learning. Nature, Feb. 2015.
[Moo65] G. Moore. Cramming more components onto integrated circuits. Electronics, Apr. 1965.
[Moo75] G. Moore. Progress in digital integrated electronics. Technical Digest, Sep. 1975.
[MPG+20] R. Mor, E. Peterfreund, M. Gavish, and A. Globerson. Optimal strategies against generative attacks. ICLR, Feb. 2020.
[MQS+18] S. Moradi, N. Qiao, F. Stefanini, and G. Indiveri. A scalable multicore architecture with heterogeneous memory wtructures for dynamic neuromorphic asynchronous processors (DYNAPs). BCS, Feb. 2018.
[MYP+19] A. Morcos, H. Yu, M. Paganini, and Y. Tian. One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers. NeurIPS, Dec. 2019.
[Mor19] T. Morgan. Nvidia shows off tech chops with RC18 inference chip. Next Platform, Sep. 2019.
[MNW+18] P. Moritz, R. Nishihara, S. Wang, et al. Ray: a distributed framework for emerging AI applications. OSDI, Sep. 2018.
[Mos17] R. Mosic. Deep reinforcement learning based trading application at JP Morgan Chase. July 2017.
[MY17] T. Munkhdalai and H. Yu. Meta networks. ICML, June 2017.
[NvB+19] M. Nagel, M. van Baalen, T. Blankevoort, and M. Welling. Data-free quantization through weight equalization and bias correction. CVPR, Nov. 2019.
[NIG+18] D. Nagy, G. Indalecio, A. Garcia-Loureiro, M. Elmessary, K. Kalna, and N. Seoane. FinFET versus gate-all-around nanowire FET: performance, scaling, and variability. EDS, Feb. 2018.
[Nak19] P. Nakkiran. Adversarial robustness may be at odds with simplicity. Jan. 2019.
[NKB+20] P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever. Deep double descent: where bigger models and more data hurt. ICLR, Apr. 2020.
[Nar19] N. Narayanan. How to recognize AI snake oil. 2019.
[NSA+19] A. Nassif, I. Shahin, I. Attili, M. Azzeh, and K. Shaalan. Speech recognition using deep neural networks: a systematic review. Access, 2019.
[NMS+19] M. Naumov, D. Mudigere, H. Shi, et al. Deep learning recommendation model for personalization and recommendation systems. May 2019.
[NKM+20] M. Naumov, J. Kim, D. Mudigere, et al. Deep learning training in Facebook data centers: design of scale-up and scale-out systems. Mar. 2020.
[Nay19] P. Nayak. Understanding searches better than ever before. Oct. 2019.
[Nea95] R. Neal. Bayesian learning for neural networks. Ph.D. Thesis, University of Toronto, 1995.
[NMZ19] E. Neftci, H. Mostafa, and F. Zenke. Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. SPM, Nov. 2019.
[NDC+17] J. Novikova, O. Dusek, A. Curry, and V. Rieser. Why we need new evaluation metrics for NLG. July 2017.
[NKJ+19] E. Nurvitadhi, D. Kwon, A. Jafari, et al. Why compete when you can work together: FPGA-ASIC integration for persistent RNNs. FCCM, May 2019.
[Nvi15] Nvidia. PTX and SASS assembly debugging. 2015.
[Nvi20] Nvidia. RAPIDS. 2020.
[Nvi20b] Nvidia. T4. 2020.
[Nvi20c] Nvidia. Data center deep learning product performance. July 2020.
[OPM02] T. Ojala, M. Pietik\"ainen, and T. Maenpaa. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. PAMI, July 2002.
[OSJ+18] C. Olah, A. Satyanarayan, I. Johnson, S. Carter, L. Schubert, K. Ye, and A. Mordvintsev. The building blocks of interpretability. 2018.
[Ope18] OpenAI. Kinds of RL algorithms. 2018.
[Orr99] G. Orr. Momentum and Learning Rate Adaptation. {Willamette University}, 1999.
[Pad19] S. Padmanabhan. Building a product catalog: eBay's university machine learning competition. Oct. 2019.
[PdN18] M. Paganini, L. de Oliveira, and B. Nachman. Accelerating science with generative adversarial networks: an application to 3D particle showers in multi-layer calorimeters. PRL, Jan. 2018.
[PY10] S. Pan and Q. Yang. A survey on transfer learning. TKDE, Oct. 2010.
[PMW+16] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami. Distillation as a defense to adversarial perturbations against deep neural networks. S\&P, Mar. 2016.
[PCZ+19] D. Park, W. Chan, Y. Zhang, C. Chiu, B. Zoph, E. Cubuk, and Q. Le. SpecAugment: a simple data augmentation method for automatic speech recognition. Apr. 2019.
[PNB+18] J. Park, M. Naumov, P. Basu, S. Deng, et al. Deep learning inference in Facebook data centers: characterization, performance optimizations and hardware implications. Nov. 2018.
[PRH+17] A. Pedram, S. Richardson, M. Horowitz, S. Galal, and S. Kvatinsky. Dark memory and accelerator-rich system optimization in the dark silicon era. D\&T, May 2016.
[PSC+19] M. Pellauer, Y. Shao, J. Clemons, et al. Buffets: an efficient and composable storage idiom for explicit decoupled data orchestration. ASPLOS, Apr. 2019.
[PSM14] J. Pennington, R. Socher, and C. Manning. GloVe: global vectors for word representation. EMNLP, 2014.
[PGZ+18] H. Pham, M. Guan, B. Zoph, Q. V. Le, and J. Dean. Efficient neural architecture search via parameter sharing. Feb. 2018.
[Phi18] M. Phi. Illustrated guide to LSTM's and GRU's: a step by step explanation. TDS. Sep. 2018.
[PPG+17] W. Ping, K. Peng, A. Gibiansky, S. Arik, A. Kannan, S. Narang, J. Raiman, and J.Miller. Deep Voice 3: scaling text-to-speech with convolutional sequence learning. Oct. 2017.
[PPC18] W. Ping, K. Peng, and J. Chen. ClariNet: parallel wave generation in end-to-end text-to-speech. July 2018.
[Pol99] F. Pollack. New microarchitecture challenges in the coming generations of CMOS process technologies. MICRO, Nov. 1999.
[PZK+17] R. Prabhakar, Y. Zhang, D. Koeplinger, et al. Plasticine: a reconfigurable architecture for parallel patterns. SIGARCH, June 2017.
[PHX+18] V. Pratap, A. Hannun, Q. Xu, et al. wav2letter++: the fastest open-source speech recognition system. Dec. 2018.
[Qia99] N. Qian. On the momentum term in gradient descent learning algorithms. Jan. 1999.
[RMC15] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. ICIGP, Nov. 2015.
[RWC+19] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners. 2019.
[RSR+19] C. Raffel, N. Shazeer, A. Roberts, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. Oct. 2019.
[RBA+13] J. Ragan-Kelley, C. Barnes, A. Adams, S. Paris, F. Durand, and S. Amarasinghe. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. PLDI, June 2013.
[RZQ+19] K. Rakelly, A. Zhou, D. Quillen, C. Finn, and S. Levine. Efficient off-policy meta-reinforcement learning via probabilistic context variables. Mar. 2019.
[ROR+16] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi. XNOR-Net: ImageNet classification using binary convolutional neural networks. ECCV, Sep. 2016.
[RD19] S. Raza and C. Ding. Progress in context-aware recommender systems-an overview. Jan. 2019.
[RAH+19] E. Real, A. Aggarwal, Y. Huang, and Q. Le. Regularized evolution for image classifier architecture search. AAAI, Feb. 2019.
[RKK19] S. Reddi, S. Kale, and S. Kumar. On the convergence of Adam and beyond. ICLR, Apr. 2019.
[RDG+16] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: unified, real-time object detection. CVPR, 2016.
[RF18] J. Redmon and A. Farhadi. YOLOv 3: an incremental improvement. Apr. 2018.
[RHG+15] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: towards real-time object detection with region proposal networks. NeurIPS, Dec. 2015.
[RAA+19] C. Renggli, S. Ashkboos, M. Aghagolzadeh, D. Alistarh, and T. Hoefler. SparCML: high-performance sparse communication for machine learning. SC, Aug. 2019.
[RKL+18] A. Rodriguez, T. Kacprzak, A. Lucchi, et al. Fast cosmic web simulations with generative adversarial networks. CompAC, Nov. 2018.
[RKB+09] B. Rogers, A. Krishna, G. Bell, K. Vu, X. Jiang, and Y. Solihin. Scaling the bandwidth wall: challenges in and avenues for CMP scaling. SIGARCH, Jun. 2009.
[RDK+19] D. Rolnick, P. Donti, L. Kaack, et al. Tackling climate change with machine learning. Nov. 2019.
[RDK+19] D. Rolnick, P. Donti, L. Kack, et al. Tackling climate change with machine learning workshop. NeurIPS, Dec. 2019.
[RFB15] O. Ronneberger, P. Fischer, and T. Brox. U-Net convolutional networks for biomedical image segmentation. May 2015.
[Ros20] C. Rosset. Turing-NLG: a 17-billion-parameter language model by Microsoft. Feb. 2020.
[RXT19] B. Roune and XLA Team. Compiling ML with XLA. Feb. 2019.
[RJP19] K. Roy, A. Jaiswal, and P. Panda. Towards spike-based machine intelligence with neuromorphic computing. Nature, 2019.
[Rud17] S. Ruder. An overview of multi-task learning in deep neural networks. June 2017.
[Rup20] K. Rupp. Microprocessor trend data. 2020.
[RDS+15] O. Russakovsky, J. Deng, H. Su, et al. Large scale visual recognition challenge. IJCV, 2015.
[RRS+19] A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell. Meta-learning with latent embedding optimization. ICLR, Mar. 2019.
[Sam16] Samgsung. Samsung begins mass producing world's fastest DRAM-based on newest high bandwidth memory (HBM) interface. 2016.
[SST09] P. Sanders, J. Speck, and J. Traff. Two-tree algorithms for full bandwidth broadcast, reduction and scan. Sep. 2009.
[SDC+19] V. Sanh, L. Debut, J. Chaumond, and T. Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. Oct. 2019.
[San19] V. Sanh. Smaller, faster, cheaper, lighter: introducing DistilBERT, a distilled version of BERT. Medium, Aug. 2019.
[Sas19] K. Sasaki. Federated Learning with TensorFlow. 2019.
[SYP17] K. Sato, C. Young, and D. Patterson. An in-depth look at Google's first Tensor Processing Unit (TPU). May 2017.
[SGT+09] F. Scarselli, M. Gori, A. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. TNNLS, Jan. 2009.
[Sch19] J. Schalkwyk. An all-neural on-device speech recognizer. Mar. 2019.
[SAH+20] J. Schrittwieser, I. Antonoglou, T. Hubert, et al. Mastering Atari, Go, Chess and Shogi by planning with a learned model. Feb. 2020.
[SKP15] F. Schroff, D. Kalenichenko, and J. Philbin. FaceNet: a unified embedding for face recognition and clustering. CVPR, Mar. 2015.
[SLM+17] J. Schulman, S. Levine, P. Moritz, M. Jordan, and P. Abbeel. Trust region policy optimization. Apr. 2017.
[SFD+14] F. Seide, H. Fu, J. Droppo, G. Li, and D. Yu. 1-bit stochastic gradient descent and application to data-parallel distributed training of speech DNNs. Int' Speech Comm. Association, Sep. 2014.
[SHB15] R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with subword units. Aug. 2015.
[SKF+16] M. Seo, A. Kembhavi, A. Farhadi, and H. Hajishirzi. Bidirectional attention flow for machine comprehension. Nov. 2016.
[SDB18] A. Sergeev and M. Del Balso. Horovod: fast and easy distributed deep learning in TensorFlow. Feb. 2018.
[SLA+19] C. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. Dahl. Measuring the effects of data parallelism on neural network training. JMLR, July 2019.
[SWR18] Y. Sharan, H. Wang, and S. Rath. GUI testing powered by deep learning. eBay Tech Blog, June 2018.
[SCP+18] N. Shazeer, Y. Cheng, N. Parmar, et al. Mesh-TensorFlow: deep learning for supercomputers. NeurIPS, Dec. 2018.
[SPW+17] J. Shen, R. Pang, R. Weiss, et al. Natural TTS synthesis by conditioning WaveNet on Mel Spectrogram predictions. ICASSP, Dec. 2017.
[SDY+19] S. Shen, Z. Dong, J. Ye, L. Ma, Z. Yao, A. Gholami, M. Mahoney, and K. Keutzer. Q-BERT: Hessian based ultra low precision quantization of BERT. Sep. 2019.
[She18] R. Sheth. Introducing PyTorch across Google Cloud. Oct. 2018.
[SLA+19] B. Shickel, T. Loftus, L. Adhikari, T. Ozrazgat-Baslanti, A. Bihorac, and P. Rashidi. DeepSOFA: a continuous acuity score for critically ill patients using clinically interpretable deep learning. Feb. 2019.
[SPP+19] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron LM training multi billion parameter language models using model parallelism. Oct. 2019.
[SL19] T. Shpeisman and C. Lattner. MLIR: multi-level intermediate representation for compiler infrastructure. Apr. 2019.
[SHM+16] D. Silver, A. Huang, C. Maddison, et al. Mastering the game of Go with deep neural networks and tree search. Nature, Jan. 2016.
[SSS+17] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, et al. Mastering the game of Go without human knowledge. Nature, Oct. 2017.
[SSS+18] D. Silver, J. Schrittwieser, K. Simonyan, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, Dec. 2018.
[SZ14] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. Sep. 2014.
[Smi17] L. Smith. Cyclical learning rates for training neural networks. WACV, Apr. 2017.
[SSZ17] J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. NeurIPS, Dec. 2017.
[Ste19] I. Steinwart. A sober look at neural network initializations. Sep. 2019.
[Ste19b] N. Stephens. BFloat16 processing for neural networks on Armv8-A. Aug. 2019.
[SA19] A. Stooke and P. Abbeel. Accelerated methods for deep reinforcement learning. Jan. 2019.
[SPE19] A. Straw, A. Procter, and R. Earhart. nGraph: unlocking next-generation performance with deep learning compilers. 2019.
[SGB+19] S. Sukhbaatar, E. Grave, P. Bojanowski, and A. Joulin. Adaptive attention span in transformers. May 2019.
[SCC+19] X. Sun, J. Choi, C. Chen, et al. Hybrid 8-bit floating point (HFP8) training and inference for deep neural networks. NeurIPS, Dec. 2019.
[SWL+19] Y. Sun, S. Wang, Y. Li, S. Feng, H. Tian, H. Wu, and H. Wang. ERNIE 2.0: a continual pre-training framework for language understanding. 2019.
[SAD+20] Y. Sun, N. Agostini, S. Dong, and D. Kaeli. Summarizing CPU and GPU design trends with product data. 2020.
[SVL14] I. Sutskever, O. Vinyals, and Q. Le. Sequence to sequence learning with neural networks. NeurIPS, Dec. 2014.
[SCY+17] V. Sze, Y. Chen, T. Yang, and J. Emer. Efficient processing of deep neural networks: a tutorial and survey. Proc. IEEE, Dec. 2017.
[SCY+20] V. Sze, Y. Chen, T. Yang, and J. Emer. Efficient processing of deep neural networks. M\&C, June 2020.
[SLJ+14] C. Szegedy, W. Liu, Y. Jia, et al. Going deeper with convolutions. CVPR, Sep. 2014.
[SVI+15] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the Inception architecture for computer vision. CVPR, Dec. 2015.
[SZS+14] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. Intriguing properties of neural networks. Feb. 2014.
[Syn17] Synced. A brief overview of attention mechanism. Medium, Sep. 2017.
[TPL19] M. Tan, R. Pang, and Q. Le. EfficientDet: scalable and efficient object detection. Nov. 2019.
[TL19] M. Tan and Q. Le. EfficientNet: rethinking model scaling for convolutional neural networks. May 2019.
[TYD+18] Y. Tassa, Y, Doron, A. Muldal, et al. DeepMind control suite. Jan. 2018.
[TKT+16] S. Tavarageri, W. Kim, J. Torrellas, and P. Sadayappan. Compiler support for software cache coherence. HiPC, Dec. 2016.
[Ter19] Terry. Inlining decisions in visual studio. July 2019.
[TRG05] R. Thakur, R. Rabenseifner, and W. Gropp. Optimization of collective communication operations in MPICH. HiPC, Feb. 2005.
[TGL+20] N. Thompson, K. Greenewald, K. Lee, and G. Manso. The computational limits of deep learning. July 2020.
[TKP+18] F. Tramer, A. Kurakin, N. Papernot, I. Goodfellow, D. Boneh, and P. McDaniel. Ensemble adversarial training: attacks and defenses. ICLR, July 2018.
[TAN+18] H. Tsai, S. Ambrogio, P. Narayanan, R. Shelby, and G. Burr. Recent progress in analog memory-based accelerators for deep learning. J. Phys. D: Appl. Phys, June 2018.
[Tsa18] S. Tsang. Review: YOLOv1 - you only look once (object detection). TDS, Oct. 2018.
[TSE+19] D. Tsipras, S. Santurkar, L. Engstrom, A. Turner, and A. Madry. Robustness may be at odds with accuracy. ICLR, Sep. 2019.
[Tvm19] TVM. TVM deep learning compiler joins Apache Software Foundation. Mar. 2019.
[Rel19] TVM. Introduction to Relay IR. 2019.
[VS19] J. Valin and J. Skoglund. LPCNet: improving neural speech synthesis through linear prediction. ICASSP, May 2019.
[vKK+16] A. van den Oord, N. Kalchbrenner, and K. Kavukcuoglu. Pixel recurrent neural networks. Jan. 2016.
[vDZ+16] A. van den Oord, S. Dieleman, H. Zen, et al. WaveNet: a generative model for raw audio. Sep. 2016.
[vLB+17] A. van den Oord, Y. Li, I. Babuschkin, et al. Parallel WaveNet: fast high-fidelity speech synthesis. Nov. 2017.
[VZT+18] N. Vasilache, O. Zinenko, T. Theodoridis, et al. Tensor Comprehensions: framework-agnostic high-performance machine learning abstractions. ICASSP, May 2019.
[VSP+17] A. Vaswani, N. Shazeer, N. Parmar, et al. Attention is all you need. NeurIPS, Dec. 2017.
[VSZ+19] R. Venkatesan, Y. Shao, B. Zimmer, et al. A 0.11 PJ/OP, 0.32-128 TOPS, scalable multi-chip-module-based deep neural network accelerator designed with a high-productivity VLSI methodology. HCS, Aug. 2019.
[Vil18] M. Villmow. Optimizing NMT with TensorRT. Mar. 2018.
[VTB+14] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: a neural image caption generator. CVPR, Nov. 2014.
[VBL+17] O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra. Matching networks for one shot learning. NeurIPS, Dec. 2017.
[VBC+19] O. Vinyals, I. Babuschkin, J. Chung, et al. AlphaStar: mastering the real-time strategy game StarCraft II. Dec. 2019.
[VAK19] A. Vladimirov, R. Asai, and V. Karpusenko. Parallel programming and optimization with Intel Xeon Phi coprocessors. Jan. 2019.
[Wal13] C. Walsh. Peter Huttenlocher (1931-2013). Nature, Oct. 2013.
[SMH+18] A.Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman. GLUE: a multi-task benchmark and analysis platform for natural language understanding. Apr. 2018.
[WYL+20] H. Wang, J. Yang, H. Lee, and S. Han. Learning to design circuits. Jan. 2020.
[WCB+18] N. Wang, J. Choi, D. Brand, C. Chen, and K. Gopalakrishnan. Training deep neural networks with 8-bit floating point numbers. NeurIPS, Dec. 2018.
[WVP+19] G. Wang, S. Venkataraman, A. Phanishayee, J. Thelin, N. Devanur, and I. Stoica. Blink: fast and generic collectives for distributed ML. Oct. 2019.
[WYZ+17] J. Wang, L. Yu, W. Zhang, Y. Gong, Y. Xu, B. Wang, P. Zhang, and D. Zhang. IRGAN: a minimax game for unifying generative and discriminative information retrieval models. SIGIR, May 2017.
[WML+19] Y. Wang, A. Mohamed, D. Le, et al. Transformer-based acoustic modeling for hybrid speech recognition. Oct. 2019.
[WYK+19] Y. Wang, Q. Yao, J. Kwok, and L. Ni. Generalizing from a few examples: a survey on few-shot learning. Comp. Surveys, May 2019.
[WWB19] Y. Wang, G. Wei, and D. Brooks. Benchmarking TPU, GPU, and CPU platforms for deep learning. Oct. 2019.
[WSS+17] Y. Wang, R. Skerry-Ryan, D. Stanton, et al. Tacotron: towards end-to-end speech synthesis. Mar. 2017.
[WWS+19] Y. Wang, Q. Wang, S. Shi, X. He, Z. Tang, K. Zhao, and X. Chu. Benchmarking the performance and power of AI accelerators for AI training. Nov. 2019.
[WSA18] R. Wei, L. Schwartz, and V. Adve. DLVM: a modern compiler infrastructure for deep learning systems. ICLR, Apr. 2018.
[WWW+16] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li. Learning structured sparsity in deep neural networks. NeurIPS, Dec. 2016.
[WXY+17] W. Wen, C. Xu, F. Yan, C. Wu, Y. Wang, Y. Chen, and H. Li. TernGrad: ternary gradients to reduce communication in distributed deep learning. NeurIPS, Dec. 2017.
[Wen17] L. Weng. From GAN to WGAN. Aug. 2017.
[Wik11] Wikimedia. Kernel Machine.svg. 2011.
{kind=link}
[Wik12] Wikimedia. Cart-pendulum.svg. 2012.
{kind=link}
[Wik15] Wikimedia. Typical cnn.png. 2015.
{kind=link}
[Wik17] Wikimedia. MnistExamples.png. 2017.
{kind=link}
[Wik18] Wikimedia. Spectrogram-19thC.png. 2018.
{kind=link}
[Wik19] Wikipedia. Apple A13. 2019.
[Wik20] Wikipedia. Authors Guild, Inc. v. Google, Inc. Feb. 2020.
[Wik20b] Wikipedia. RankBrain. Feb. 2020.
[WWP09] S. Williams, A. Waterman, and D. Patterson. Roofline: an insightful visual performance model for multicore architectures. ACM, Apr. 2009.
[WRS+18] A. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht. The marginal value of adaptive gradient methods in machine learning. NeurIPS, Dec. 2018.
[WZL+19] R. Wilson, C. Zhang, W. Lam, D. Desfontaines, D. Simmons-Marengo, and B. Gipson. Differentially private SQL with bounded user contribution. Nov. 2019.
[Win20] P. Winder. \MYhref{https://rl-book.com}{Reinforcement Learning: industrial applications of intelligent agents}. O'Reilly, Nov. 2020.
[Wri19] L. Wright. New deep learning optimizer, Ranger synergistic combination of RAdam + LookAhead for the best of both. Aug. 2019.
[WZX+16] J. Wu, C. Zhang, T. Xue, W. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. NeurIPS, Dec. 2016.
[WSC+16] Y. Wu, M. Schuster, Z. Chen, et al. Google's neural machine translation system: bridging the gap between human and machine translation. Sep. 2016.
[WAB+17] C. Wu, A. Ahmed, A. Beutel, A. Smola, and H. Jing. Recurrent recommender networks. WSDM, Feb. 2017.
[WWF+17] S. Wu, J. Wieland, O. Farivar, and J. Schiller. Automatic alt-text: computer-generated image descriptions for blind users on a social network service. CSCW, Feb. 2017.
[WH18] Y. Wu and K. He. Group normalization. ECCV, Mar. 2018.
[WZZ+19] B. Wu, X. Zhou, S. Zhao, X. Yue, and K. Keutzer. SqueezeSegV.2: improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud. ICRA, May 2019.
[WFB+19] F. Wu, A. Fan, A. Baevski, Y. Dauphin, and M. Auli. Pay less attention with lightweight and dynamic convolutions. Jan. 2019.
[WKM+19] Y. Wu, A. Kirillov, F. Massa, W. Lo, and R. Girshick. Detectron2. 2019.
[WKM+19] Y. Wu, A. Kirillov, F. Massa, W. Lo, and R. Girshick. Detectron.2: a PyTorch-based modular object detection library. 2019.
[Wu19] H. Wu. Low precision inference on GPU. GTC, Mar. 2019.
[WDZ+19] B. Wu, X. Dai, P. Zhang, et al. FBNet: hardware-aware efficient ConvNet design via differentiable neural architecture search. CVPR, May 2019.
[WM95] W. Wulf and S. McKee. Hitting the memory wall: implications of the obvious. SIGARCH, Mar. 1995.
[XYB+19] S. Xi, Y. Yao, K. Bhardwaj, P. Whatmough, G. Wei, and D. Brooks. SMAUG: end-to-end full-stack simulation infrastructure for deep learning workloads. Dec. 2019.
[XZZ20] C. Xiao, P. Zhong, and C. Zheng. Enhancing adversarial defense by k-winners-take-all. ICLR, Feb. 2020.
[XGD+17] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. CVPR, July 2017.
[Xil19] Xilinx. Versal: the first adaptive compute acceleration platform (ACAP). 2019.
[XAT+18] C. Xing, D. Arpit, C. Tsirigotis, and Y. Bengio. A walk with SGD. May 2018.
[XEQ17] W. Xu, D. Evans, and Y. Qi. Feature squeezing: detecting adversarial examples in deep neural networks. Dec. 2017.
[XLF+18] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song. Neural network-based graph embedding for cross-platform binary code similarity detection. CCS, July 2018.
[YKT+18] M. Yamazaki, A. Kasagi, A. Tabuchi, et al. Yet another accelerated SGD: ResNet-50 training on ImageNet in 74.7 seconds. Mar. 2019.
[Yam12] R. Yampolskiy. Turing test as a defining feature of AI-Completeness. SCI, 2012.
[YCS17] T. Yang, Y. Chen, and V. Sze. Designing energy-efficient convolutional neural networks using energy-aware pruning. CVPR, Apr. 2017.
[YDY+19] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. Le. XLNet: generalized autoregressive pretraining for language understanding. NeurIPS, Dec. 2019.
[YHG+15] Z. Yang, X. He, J. Gao, L. Deng, and A. Smola. Stacked attention networks for image question answering. CVPR, Nov. 2015.
[YGL+18] Z. Yao, A. Gholami, Q. Lei, K. Keutzer, and M. Mahoney. Hessian-based Analysis of large batch training and robustness to adversaries. NeurIPS, Dec. 2018.
[YGS+20] Z. Yao, A. Gholami, S. Shen, K. Keutzer, and M. Mahoney. AdaHessian: an adaptive second order optimizer for machine learning. Jun. 2020.
[YSE+20] J. Yin, S. Sethumurugan, Y. Eckert, N. Enright Jerger, et al. Experiences with ML-driven design: a NoC case study. HPCA, Feb. 2020.
[YKC+18] C. Ying, S. Kumar, D. Chen, T. Wang, and Y. Cheng. Image classification at supercomputer scale. NeurIPS, Dec. 2018.
[YGG17] Y. You, I. Gitman, and B. Ginsburg. Large batch training of convolutional networks. Sep. 2017.
[YLR+20] Y. You, J. Li, S. Reddi, et al. Large batch optimization for deep learning: training BERT in 76 minutes. ICLR, Jan. 2020.
[YZH+18] Y. You, Z. Zhang, C. Hsieh, J. Demmel, and K. Keutzer. ImageNet training in minutes. Jan. 2018.
[YAB+18] Y. Yu, M. Abadi, P. Barham, et al. Dynamic control flow in large-scale machine learning. EUROSYS, May 2018.
[YTL+19] L. Yuan, F. Tay, G. Li, T. Wang, and J. Feng. Revisit knowledge distillation: a teacher-free framework. Sep. 2019.
[ZK15] S. Zagoruyko and N. Komodakis. Learning to compare image patches via convolutional neural networks. CVPR, June 2015.
[ZXL+18] N. Zeghidour, Q. Xu, V. Liptchinsky, N. Usunier, G. Synnaeve, and R. Collobert. Fully convolutional speech recognition. Dec. 2018.
[Zei12] M. Zeiler. ADADELTA: an adaptive learning rate method. Dec. 2012.
[ZF13] M. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. ECCV, Nov. 2013.
[ZF13] M. Zeiler and R. Fergus. Stochastic pooling for regularization of deep convolutional neural networks. ICLR, May 2013.
[ZES+20] A. Zela, T. Elsken, T. Saikia, Y. Marrakchi, T. Brox, and F. Hutter. Understanding and robustifying differentiable architecture search. ICLR, Jan. 2020.
[ZB19] T. Zerrell and J. Bruestle. Stripe: tensor compilation via the nested polyhedral model. Mar. 2019.
[ZDH19] B. Zhang, A. Davoodi, and Y. Hu. Efficient inference of CNNs via channel pruning. Aug. 2019.
[ZYY18] J. Zhang, J. Yang, and H. Yuen. Training with low-precision embedding tables. NeurIPS, Dec. 2018.
[ZRW+18] M. Zhang, S. Rajbhandari, W. Wang, and Y. He. DeepCPU: serving RNN-based deep learning models 10x faster. ATC, 2018.
[ZLH+19] M. Zhang, J. Lucas, G. Hinton, and J. Ba. Lookahead optimizer: k steps forward, 1 step back. NeurIPS, Dec. 2019.
[ZL19] W. Zhang and P. Li. Spike-train level backpropagation for training deep recurrent spiking neural networks. NeurIPS, Dec. 2019.
[ZZL+17] X. Zhang, X. Zhou, M. Lin, and J. Sun. ShuffleNet: an extremely efficient convolutional neural network for mobile devices. CVPR, July 2017.
[ZXH+17] Y. Zhang, T. Xiang, T. Hospedales, and H. Lu. Deep mutual learning. CVPR, Jan. 2018.
[ZZZ+19] C. Zhao, S. Zhao, M. Zhao, Z. Chen, C. Gao, H. Li, and Y. Tan. Secure multi-party computation: theory, practice and applications. Inf. Sciences, Feb. 2019.
[ZZX+19] W. Zhao, J. Zhang, D. Xie, Y. Qian, R. Jia, and P. Li. AIBox: CTR prediction model training on a single node. CIKM, Nov. 2019.
[ZHW+19] Z. Zhao, L. Hong, L. Wei, et al. Recommending what video to watch next: a multitask ranking system. RecSys, Sep. 2019.
[ZZZ+18] G. Zheng, F. Zhang, Z. Zheng, Y. Xiang, N. Yuan, X. Xie, and Z. Li. DRN: a deep reinforcement learning framework for news recommendation. IW3C2, Apr. 2018.
[ZMF+18] G. Zhou, N. Mou, Y. Fan, Q. Pi, W. Bian, C. Zhou, X. Zhu, and K. Gai. Deep interest evolution network for click-through rate prediction. AAAI, Nov. 2018.
[ZZY+19] R. Zhu, K. Zhao, H. Yang, W. Lin, C. Zhou, B. Ai, Y. Li, and J. Zhou. AliGraph: a comprehensive graph neural network platform. PVLDB, Aug. 2019.
[ZTZ+18] Z. Zhuang, M. Tan, B. Zhuang, J. Liu, Y. Guo, Q. Wu, J. Huang, and J. Zhu. Discrimination aware channel pruning for deep neural networks. NeurIPS, Dec. 2018.
[Zis18] A. Zisserman. Self-supervised learning. July 2018.
[ZL17] B. Zoph, and Q. Le. Neural Architecture Search with Reinforcement Learning. ICLR, Feb. 2017.